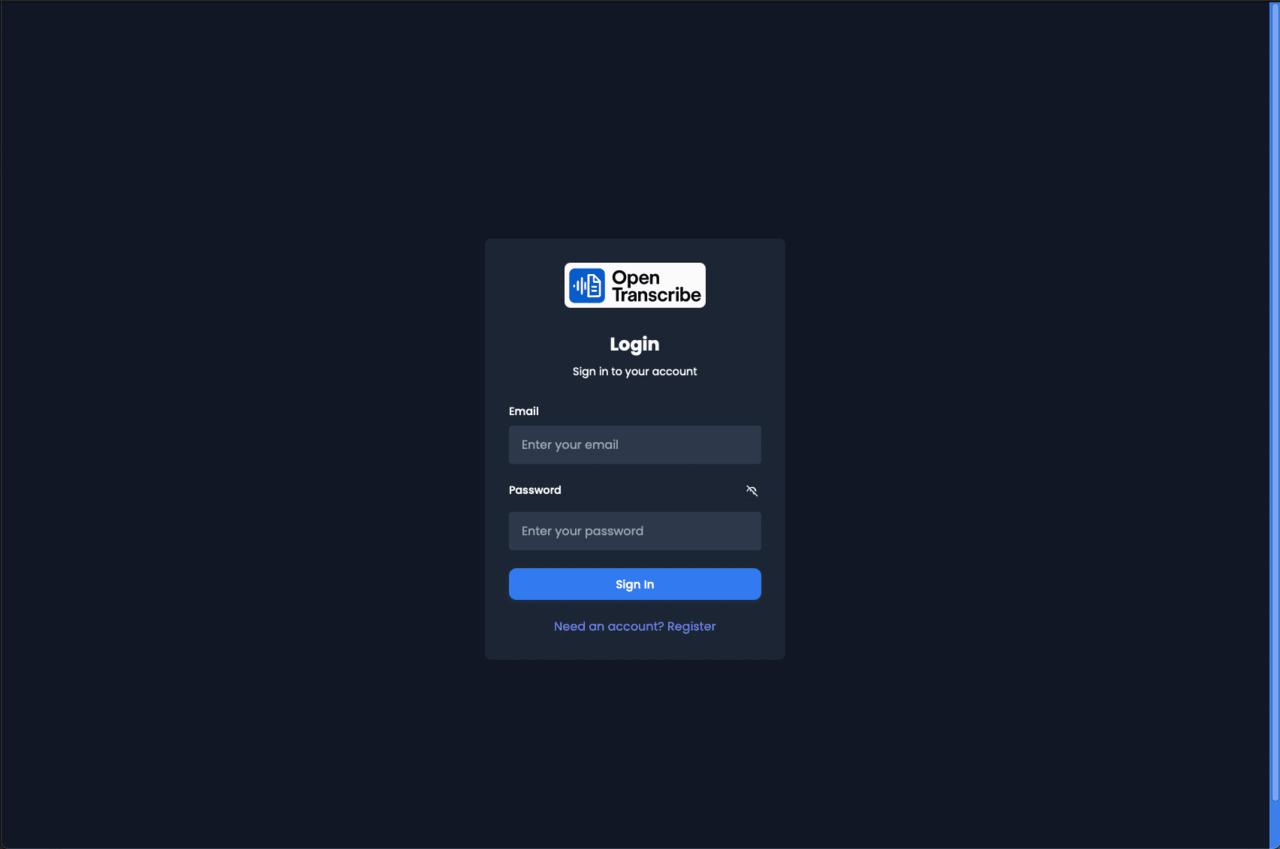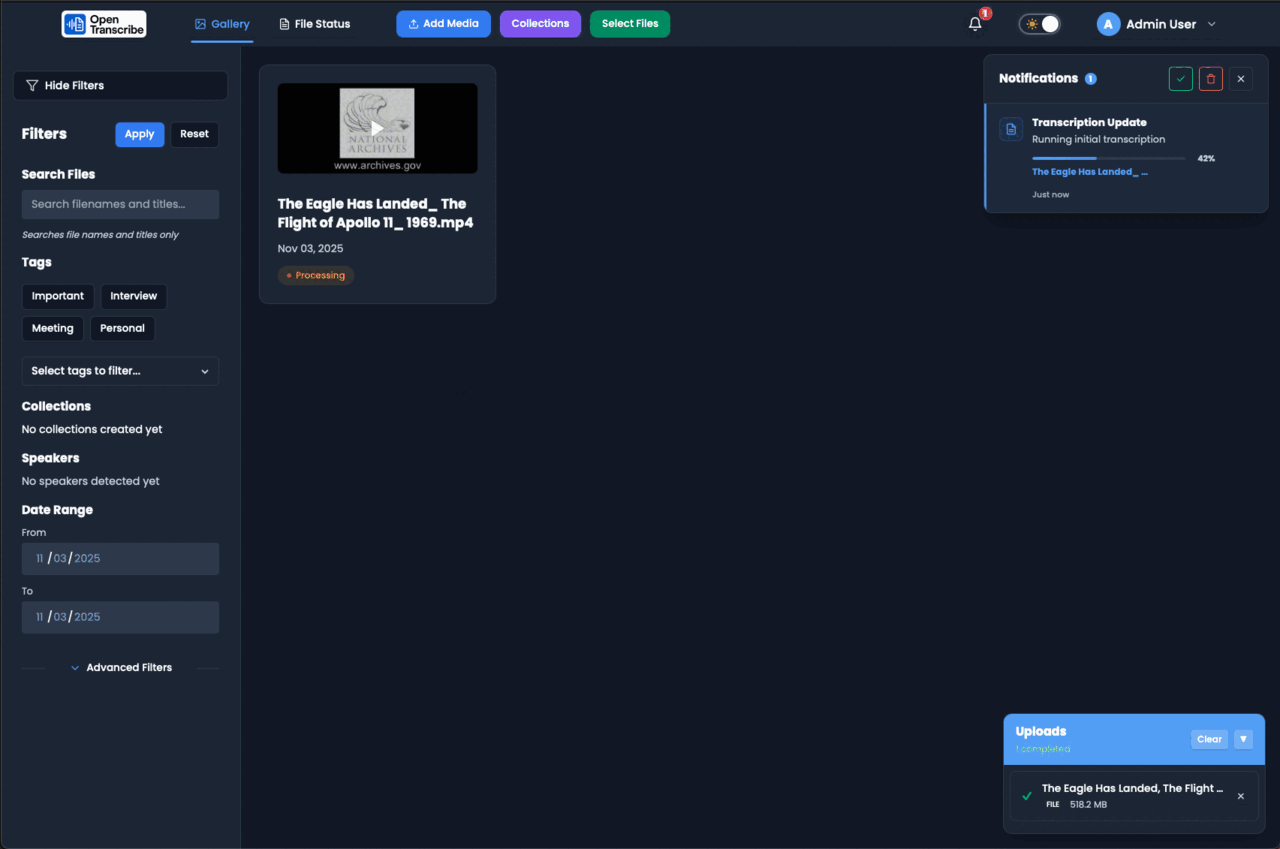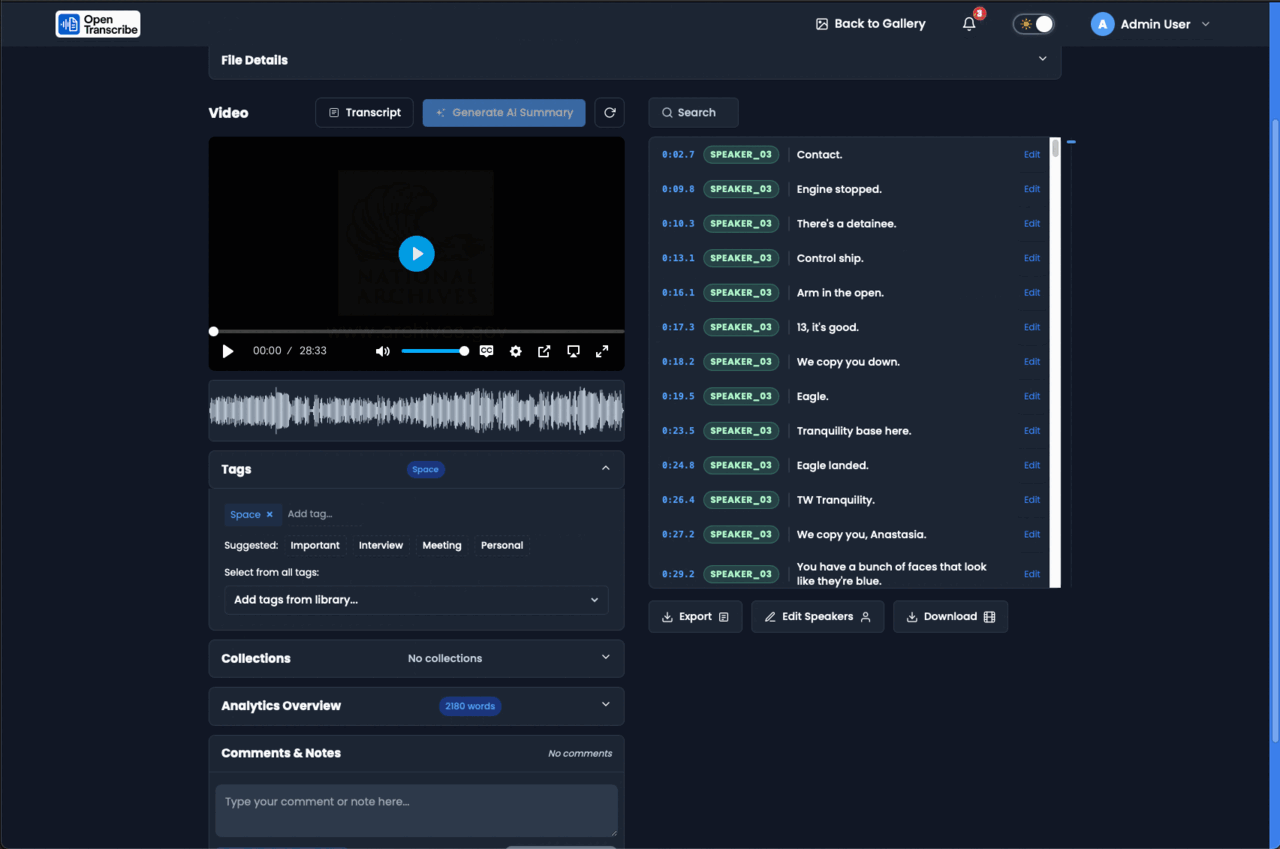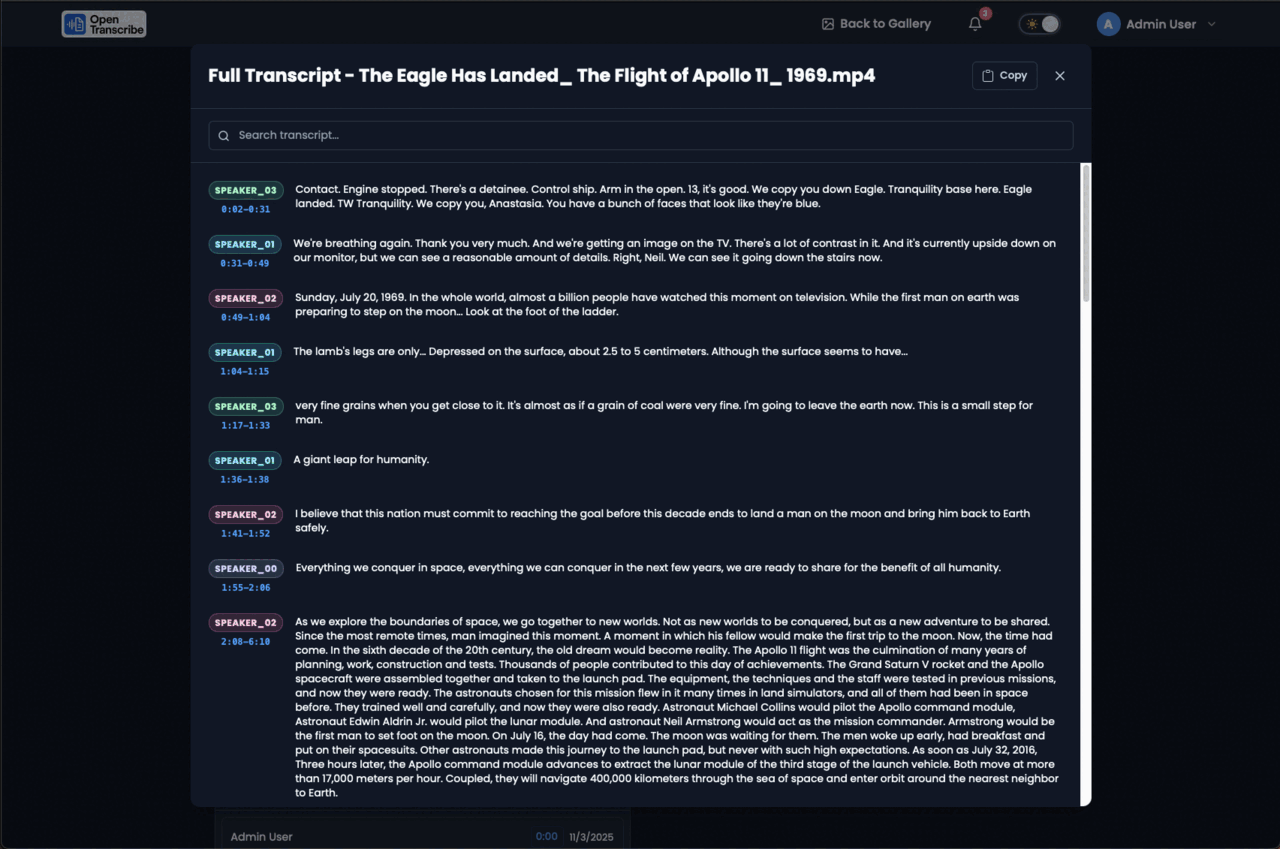
What you get
A complete transcription platform, not just a Whisper wrapper.
WhisperX with word-level timestamps across 100+ languages. Native cross-attention alignment, 70x realtime on GPU, configurable models.
PyAnnote v4 diarization with cross-video voice fingerprinting. GPU-accelerated clustering, gender classification, and automatic profile matching.
BLUF summaries, action item extraction, auto-labeling. Works with OpenAI, Claude, vLLM, Ollama, or OpenRouter. Bring your own model.
Full-text and semantic search across all transcripts. BM25 + neural vectors merged via Reciprocal Rank Fusion on OpenSearch.
LDAP/AD, Keycloak OIDC, PKI/X.509, MFA. FedRAMP-aligned controls, AES-256-GCM encryption, audit logging, FIPS 140-3 ready.
Docker Compose deployment. Multi-GPU scaling, 3-stage Celery pipeline, health monitoring. Runs air-gapped. Your data, your servers.
Use cases
Speaker-attributed transcripts with action items
Subtitles, indexing, and podcast transcription
Depositions, audit trails, FIPS compliance
Interview analysis and multilingual support
Air-gapped, PKI auth, classification banners
High-volume analysis and trend detection
Open stack, zero lock-in
Every component is open source. Deploy on bare metal, in your cloud, or fully air-gapped. Same Docker Compose config scales from a laptop to a multi-GPU rack.
- 3-stage Celery chain separates CPU and GPU work
- Multi-GPU worker scaling with configurable concurrency
- Automatic Alembic migrations on startup
- Non-root containers, health checks, Flower monitoring
- Offline deployment with pre-cached models
Transcription and speaker diarization
Full-text and neural vector search
7-queue task pipeline (GPU/CPU split)
Relational storage with Alembic migrations
S3-compatible object storage, AES-256
Frontend and async API backend
How it compares
Feature comparison with commercial platforms and open source alternatives
| Feature | Open- Transcribe | Commercial | Open Source | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Otter.ai | Rev | Descript | Sonix | Trint | Vibe | Scriberr | LinTO | Whishper | Mac- Whisper | ||
| Speaker diarization | -- | Pro | |||||||||
| Word-level timestamps | -- | -- | |||||||||
| 100+ languages | -- | 20+ | 49+ | 50+ | |||||||
| AI summarization | -- | -- | -- | -- | Pro | ||||||
| Custom LLM providers | -- | -- | -- | -- | -- | -- | -- | -- | |||
| Full-text + semantic search | -- | -- | -- | -- | -- | -- | -- | text | |||
| Cross-video speaker matching | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Self-hosted / air-gapped | -- | -- | -- | -- | -- | -- | |||||
| Enterprise auth (LDAP/PKI/OIDC) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Multi-user / roles | -- | -- | -- | -- | -- | -- | -- | -- | |||
| Multi-GPU scaling | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Cloud ASR providers | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| URL import (YouTube etc.) | -- | -- | -- | -- | -- | -- | -- | -- | Pro | ||
| Docker Compose deploy | -- | -- | -- | -- | -- | -- | -- | ||||
| Desktop app | -- | -- | -- | -- | -- | -- | -- | -- | -- | ||
| Subtitle editor | -- | -- | -- | -- | -- | -- | -- | -- | -- | ||
| SOC 2 / ISO 27001 | -- | -- | -- | -- | -- | -- | -- | ||||
Data based on publicly available documentation as of March 2026. Features may vary by plan or version.
Own your transcription pipeline
Deploy in under 5 minutes. No account needed, no data leaves your servers.